

 Twitter
Twitter Mailinglist
Mailinglist
Hack-a-LOD 2016: De hackathon met linked open erfgoed data
Heb jij een goed idee hoe de digitale collecties van erfgoedinstellingen met elkaar verbonden kunnen worden? Doe dan mee aan Hack-a-LOD op 11 en 12 november aanstaande in een voormalig gevangeniscomplex. De Koninklijke Bibliotheek (KB) organiseert samen met het Netwerk
Hack-a-LOD 2016: De hackathon met linked open erfgoed data
Heb jij een goed idee hoe de digitale collecties van erfgoedinstellingen met elkaar verbonden kunnen worden? Doe dan mee aan Hack-a-LOD op 11 en 12 november aanstaande in een voormalig gevangeniscomplex. De Koninklijke Bibliotheek (KB) organiseert samen met het Netwerk

Open Data Beleid als doel van Open Cultuur Data
Op 19 september hield Open Cultuur Data de laatste inhoudelijke bijeenkomst van de Open Cultuur Data masterclasses voor het Netwerk Digitaal Erfgoed. Tijdens deze laatste sessie kwamen de argumenten die over tafel gaan voor en tegen het adopteren van een
Open Data Beleid als doel van Open Cultuur Data
Op 19 september hield Open Cultuur Data de laatste inhoudelijke bijeenkomst van de Open Cultuur Data masterclasses voor het Netwerk Digitaal Erfgoed. Tijdens deze laatste sessie kwamen de argumenten die over tafel gaan voor en tegen het adopteren van een

Spelen met open cultuur data: nieuwe technologie
Door: Tijmen Schep. Samen met Beeld en Geluid en de Open State Foundation organiseert Kennisland al enkele jaren het Open Cultuur Data Lab. Daarin onderzoeken we samen met musea, archieven en andere kennisinstellingen de Open Data beweging en wat die
Spelen met open cultuur data: nieuwe technologie
Door: Tijmen Schep. Samen met Beeld en Geluid en de Open State Foundation organiseert Kennisland al enkele jaren het Open Cultuur Data Lab. Daarin onderzoeken we samen met musea, archieven en andere kennisinstellingen de Open Data beweging en wat die
Publicatie: Onderzoek naar Open Data van Nederlandse GLAM instellingen
Tien masterstudenten van de opleiding Culturele Informatiewetenschap aan de Universiteit van Amsterdam hebben in januari 2016 onderzoek gedaan naar open data van Nederlandse erfgoedinstellingen. Zij onderzochten tools en praktijken rondom het aanbieden van open data en wat de impact van
Publicatie: Onderzoek naar Open Data van Nederlandse GLAM instellingen
Tien masterstudenten van de opleiding Culturele Informatiewetenschap aan de Universiteit van Amsterdam hebben in januari 2016 onderzoek gedaan naar open data van Nederlandse erfgoedinstellingen. Zij onderzochten tools en praktijken rondom het aanbieden van open data en wat de impact van

HollandCall: Hergebruik Noord-Hollandse Cultuurdata
Wil jij bijdragen aan het laten herleven van het rijke culturele erfgoed in Noord-Holland? Wil jij toeristische open data of open cultuurdata hergebruiken? Doe dan mee aan HollandCall. Het innovatieprogramma van de provincie Noord-Holland waarmee je een succesvol product of dienst
HollandCall: Hergebruik Noord-Hollandse Cultuurdata
Wil jij bijdragen aan het laten herleven van het rijke culturele erfgoed in Noord-Holland? Wil jij toeristische open data of open cultuurdata hergebruiken? Doe dan mee aan HollandCall. Het innovatieprogramma van de provincie Noord-Holland waarmee je een succesvol product of dienst
EC verwijst naar Open Cultuur Data als voorbeeldig initiatief rond de online toegankelijkheid van digitaal erfgoed
In een recent voortgangsrapport van de Europese Commissie over de ontwikkelingen rond de digitalisering, online beschikbaarstelling en digitale duurzaamheid van cultureel erfgoed wordt naar Open Cultuur Data als een voorbeeldig initiatief rond de online toegankelijkheid van digitaal erfgoed verwezen. Het rapport beschrijft
EC verwijst naar Open Cultuur Data als voorbeeldig initiatief rond de online toegankelijkheid van digitaal erfgoed
In een recent voortgangsrapport van de Europese Commissie over de ontwikkelingen rond de digitalisering, online beschikbaarstelling en digitale duurzaamheid van cultureel erfgoed wordt naar Open Cultuur Data als een voorbeeldig initiatief rond de online toegankelijkheid van digitaal erfgoed verwezen. Het rapport beschrijft

Open Cultuur Data Lab sessie: Juridische kaders
22 deelnemers van 17 culturele instellingen startten in april met het Open Cultuur Data Lab. In vier sessies leren zij alles over open data, auteursrecht, techniek en beleidsvorming. Deze sessies, verzorgd door Kennisland en Nederlands Instituut voor Beeld en Geluid
Open Cultuur Data Lab sessie: Juridische kaders
22 deelnemers van 17 culturele instellingen startten in april met het Open Cultuur Data Lab. In vier sessies leren zij alles over open data, auteursrecht, techniek en beleidsvorming. Deze sessies, verzorgd door Kennisland en Nederlands Instituut voor Beeld en Geluid

Regionaal Archief Alkmaar geeft beeldcollecties vrij na Masterclass
Door: Malk Alphenaar (Regionaal Archief Alkmaar) Het Regionaal Archief Alkmaar vindt dat haar collectie van iedereen is en dan eenieder er gebruik van moet kunnen maken (bron: jaarverslag 2014). Maar hoe zorg je ervoor dat iedereen makkelijk bij je collecties
Regionaal Archief Alkmaar geeft beeldcollecties vrij na Masterclass
Door: Malk Alphenaar (Regionaal Archief Alkmaar) Het Regionaal Archief Alkmaar vindt dat haar collectie van iedereen is en dan eenieder er gebruik van moet kunnen maken (bron: jaarverslag 2014). Maar hoe zorg je ervoor dat iedereen makkelijk bij je collecties

De laatste Masterclass: waar zijn we nu?
Terwijl in het Pakhuis de Zwijger het Doe Open Festival aan de gang was, werd op het Marineterrein de laatste Masterclass gehouden. Deze middag vertelde de deelnemers hoe hun instellingen ervoor staan wat betreft open data, werden tips uitgewisseld en
De laatste Masterclass: waar zijn we nu?
Terwijl in het Pakhuis de Zwijger het Doe Open Festival aan de gang was, werd op het Marineterrein de laatste Masterclass gehouden. Deze middag vertelde de deelnemers hoe hun instellingen ervoor staan wat betreft open data, werden tips uitgewisseld en

GLAMetrics: Nederlands cultureel erfgoed op Wikipedia bereikt maandelijks miljoenenpubliek
Er is een groeiende behoefte in de culturele sector naar het meten van de impact van het beschikbaar stellen van collecties als open data en open content, en tegelijkertijd is er – ook internationaal – geen partij die deze gegevens
GLAMetrics: Nederlands cultureel erfgoed op Wikipedia bereikt maandelijks miljoenenpubliek
Er is een groeiende behoefte in de culturele sector naar het meten van de impact van het beschikbaar stellen van collecties als open data en open content, en tegelijkertijd is er – ook internationaal – geen partij die deze gegevens

Masterclass 5: Toeristische data
Tijdens de vijfde Masterclass werd een nieuw thema besproken: toeristische data. Maar wat is het precies, wat kan je er mee en wat levert het op? Toeristische data zorgen voor meer zichtbaarheid van de culturele instellingen, waardoor ze meer bezoekers
Masterclass 5: Toeristische data
Tijdens de vijfde Masterclass werd een nieuw thema besproken: toeristische data. Maar wat is het precies, wat kan je er mee en wat levert het op? Toeristische data zorgen voor meer zichtbaarheid van de culturele instellingen, waardoor ze meer bezoekers

Meer dan 1 miljoen objecten in de OCD-API
Vorig jaar is de Open Cultuur Data API gelanceerd, een tool om alle cultuurdata te benaderen en te bundelen, ongeacht herkomst van de data. De API is volledig open source en samen met een actieve community van gebruikers is gewerkt
Meer dan 1 miljoen objecten in de OCD-API
Vorig jaar is de Open Cultuur Data API gelanceerd, een tool om alle cultuurdata te benaderen en te bundelen, ongeacht herkomst van de data. De API is volledig open source en samen met een actieve community van gebruikers is gewerkt

Masterclass 4: Beleidsvorming
Als je als medewerker van een culturele instelling overtuigd bent van de baten van het vrijgeven van je collectie als open data dan ben je er nog niet. Hoe krijg je de rest van je organisatie zo ver om je
Masterclass 4: Beleidsvorming
Als je als medewerker van een culturele instelling overtuigd bent van de baten van het vrijgeven van je collectie als open data dan ben je er nog niet. Hoe krijg je de rest van je organisatie zo ver om je

Masterclass 3: Techniek en hergebruik
Na de eerste lentedag zondag 8 maart, volgde maandag de derde Open Cultuur Data Masterclass Noord-Holland. Dit keer werden de onderwerpen techniek en hergebruik behandeld. Een lastig onderwerp omdat het technische abstract is. Daarna kwam Hugo van Wissen, developer van
Masterclass 3: Techniek en hergebruik
Na de eerste lentedag zondag 8 maart, volgde maandag de derde Open Cultuur Data Masterclass Noord-Holland. Dit keer werden de onderwerpen techniek en hergebruik behandeld. Een lastig onderwerp omdat het technische abstract is. Daarna kwam Hugo van Wissen, developer van

Creative Commons & Intellectuele eigendommen
Maandag 16 februari vond de tweede Masterclass Open Cultuur Data Noord-Holland plaats. Deze sessie stond in het teken van intellectuele eigendomsrecht en open licenties. Wanneer kan je zonder problemen iets als open data publiceren zodat het kan worden hergebruikt en
Creative Commons & Intellectuele eigendommen
Maandag 16 februari vond de tweede Masterclass Open Cultuur Data Noord-Holland plaats. Deze sessie stond in het teken van intellectuele eigendomsrecht en open licenties. Wanneer kan je zonder problemen iets als open data publiceren zodat het kan worden hergebruikt en

UIT-API Noord-Holland
Zoeken in alle evenementen en activiteiten in Noord-Holland? De Cultuurcompagnie maakt het mogelijk met de UIT-API. Met deze API kan je gemakkelijk filteren op activiteiten in Noord-Holland. Zo zijn er filters op plaats, leeftijd en zelfs op activiteitssoort. Met de
UIT-API Noord-Holland
Zoeken in alle evenementen en activiteiten in Noord-Holland? De Cultuurcompagnie maakt het mogelijk met de UIT-API. Met deze API kan je gemakkelijk filteren op activiteiten in Noord-Holland. Zo zijn er filters op plaats, leeftijd en zelfs op activiteitssoort. Met de

Kick-off Masterclass Noord-Holland
Maandag 9 februari werd de eerste sessie van de Open Cultuur Data Masterclass Noord-Holland georganiseerd met elf erfgoedinstellingen. De Masterclass werd gehouden in het prachtig moderne gebouw van het Westfries Archief in Hoorn. Gezellig met Hoornse gebakjes en koffie of
Kick-off Masterclass Noord-Holland
Maandag 9 februari werd de eerste sessie van de Open Cultuur Data Masterclass Noord-Holland georganiseerd met elf erfgoedinstellingen. De Masterclass werd gehouden in het prachtig moderne gebouw van het Westfries Archief in Hoorn. Gezellig met Hoornse gebakjes en koffie of

Terugblikken en vooruitkijken
Op 12 januari vond de Open Cultuur Data Nieuwjaarsborrel plaats in het Amsterdamse Andaz Hotel. Nieuwjaarsbijeenkomsten zijn natuurlijk altijd de ideale gelegenheden om terug te kijken en vooruit te kijken. Het terugkijken bestond uit het prijzengeld uitreiken aan de winnaars
Terugblikken en vooruitkijken
Op 12 januari vond de Open Cultuur Data Nieuwjaarsborrel plaats in het Amsterdamse Andaz Hotel. Nieuwjaarsbijeenkomsten zijn natuurlijk altijd de ideale gelegenheden om terug te kijken en vooruit te kijken. Het terugkijken bestond uit het prijzengeld uitreiken aan de winnaars
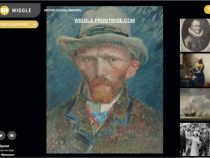
Breng afbeeldingen tot leven met Wiggle
Door: Richard Jong (Frontwise) Bij de laatste editie van de Open Cultuur Data Challenge won de applicatie Wiggle een eervolle vermelding. Wat is Wiggle, wat doet het met open cultuur data en hoe is het gegaan sinds de challenge? Wiggle
Breng afbeeldingen tot leven met Wiggle
Door: Richard Jong (Frontwise) Bij de laatste editie van de Open Cultuur Data Challenge won de applicatie Wiggle een eervolle vermelding. Wat is Wiggle, wat doet het met open cultuur data en hoe is het gegaan sinds de challenge? Wiggle

Rapport ‘Open Cultuur Data in Noord-Holland’
In oktober hebben de Open State Foundation en Kennisland in opdracht van de provincie Noord-Holland een inventarisatie uitgevoerd binnen de Noord-Hollandse culturele sector. Open Cultuur Data heeft 33 verschillende musea, archieven en historische verenigingen gesproken, van Texel tot aan Hilversum.
Rapport ‘Open Cultuur Data in Noord-Holland’
In oktober hebben de Open State Foundation en Kennisland in opdracht van de provincie Noord-Holland een inventarisatie uitgevoerd binnen de Noord-Hollandse culturele sector. Open Cultuur Data heeft 33 verschillende musea, archieven en historische verenigingen gesproken, van Texel tot aan Hilversum.

Open Cultuur Data Masterclass Noord-Holland 2015
Werk jij bij een culturele erfgoedinstelling in de provincie Noord-Holland? Wil jij meer weten over de mogelijkheden van open data voor jouw instelling? Wil jij graag met open cultuurdata aan de slag? Schrijf je dan snel in voor de Open
Open Cultuur Data Masterclass Noord-Holland 2015
Werk jij bij een culturele erfgoedinstelling in de provincie Noord-Holland? Wil jij meer weten over de mogelijkheden van open data voor jouw instelling? Wil jij graag met open cultuurdata aan de slag? Schrijf je dan snel in voor de Open

Museumn8: Apps in het Gewelf
Op zaterdag 1 november vond in Amsterdam de Museumn8 plaats. De avond om op een interactieve manier cultuur te ontdekken. Open Cultuur Data kon niet ontbreken en organiseerde voor de eerste keer de Amsterdam App Dungeon in het Amsterdam Museum.
Museumn8: Apps in het Gewelf
Op zaterdag 1 november vond in Amsterdam de Museumn8 plaats. De avond om op een interactieve manier cultuur te ontdekken. Open Cultuur Data kon niet ontbreken en organiseerde voor de eerste keer de Amsterdam App Dungeon in het Amsterdam Museum.

Presentatie onderzoeksresultaten: “Open Cultuur Data in Noord-Holland”
De Provincie Noord-Holland heeft in 2012 de ambitie uitgesproken om koploper te zijn op het gebied van open data in Nederland. In opdracht van de provincie Noord-Holland hebben Open State en Kennisland een inventarisatie uitgevoerd naar open cultuurdata bij 30
Presentatie onderzoeksresultaten: “Open Cultuur Data in Noord-Holland”
De Provincie Noord-Holland heeft in 2012 de ambitie uitgesproken om koploper te zijn op het gebied van open data in Nederland. In opdracht van de provincie Noord-Holland hebben Open State en Kennisland een inventarisatie uitgevoerd naar open cultuurdata bij 30
Doe mee met de impactmeting open cultuurdata!
Altijd al willen weten hoe vaak jullie open cultuurdata nu werkelijk gebruikt wordt? Open Cultuur Data wil samen met erfgoedinstellingen meer inzicht krijgen in het hergebruik en bereik van open cultuurdata in Nederland.
Doe mee met de impactmeting open cultuurdata!
Altijd al willen weten hoe vaak jullie open cultuurdata nu werkelijk gebruikt wordt? Open Cultuur Data wil samen met erfgoedinstellingen meer inzicht krijgen in het hergebruik en bereik van open cultuurdata in Nederland.

Challenge winnaars op Museumnacht
Op zaterdag 1 november vindt de jaarlijkse Museumnacht Amsterdam weer plaats. De winnaars van de App Challenge presenteren hun apps op deze avond in het Amsterdam Museum in de Amsterdam App Dungeon. De dungeon wordt om 19.30 uur officieel geopend. Daarna
Challenge winnaars op Museumnacht
Op zaterdag 1 november vindt de jaarlijkse Museumnacht Amsterdam weer plaats. De winnaars van de App Challenge presenteren hun apps op deze avond in het Amsterdam Museum in de Amsterdam App Dungeon. De dungeon wordt om 19.30 uur officieel geopend. Daarna

Winnaars Challenge
Na een zinderende avond met pitches van de shortlist van 12 beste apps, heeft de jury gisteren onder leiding van voorzitter Paul Spies (Amsterdam Museum) de prijswinnaars van de Open Cultuur Data Challenge bekend gemaakt.
Winnaars Challenge
Na een zinderende avond met pitches van de shortlist van 12 beste apps, heeft de jury gisteren onder leiding van voorzitter Paul Spies (Amsterdam Museum) de prijswinnaars van de Open Cultuur Data Challenge bekend gemaakt.

Meesterwerken als achtergrond op je Mac
Met de Open Cultuur Data API RSS-feed kan je eenvoudig elk half uur een ander meestwerk op je achtergrond toveren. Deze blog is alleen voor Mac OS X.
Meesterwerken als achtergrond op je Mac
Met de Open Cultuur Data API RSS-feed kan je eenvoudig elk half uur een ander meestwerk op je achtergrond toveren. Deze blog is alleen voor Mac OS X.

Open je collectie: doe mee aan het Open Cultuur Data Lab
Hoe kan het open delen van erfgoed zorgen voor meer toegankelijkheid, bereik en hergebruik onder een nieuw publiek? We nodigen professionals in de culturele sector uit om dit te onderzoeken in het Open Cultuur Data Lab. Een nieuwe generatie onderzoekers
Open je collectie: doe mee aan het Open Cultuur Data Lab
Hoe kan het open delen van erfgoed zorgen voor meer toegankelijkheid, bereik en hergebruik onder een nieuw publiek? We nodigen professionals in de culturele sector uit om dit te onderzoeken in het Open Cultuur Data Lab. Een nieuwe generatie onderzoekers

Open Data Dag Amsterdam in de Gouden Eeuw
Zaterdag 5 maart wordt de Open Data Dag gehouden. Overal in de wereld zijn er dan bijeenkomsten, waar mensen meer over open data kunnen leren, plannen kunnen maken om gegevens open te maken en samen kunnen werken om nieuwe toepassingen voor
Open Data Dag Amsterdam in de Gouden Eeuw
Zaterdag 5 maart wordt de Open Data Dag gehouden. Overal in de wereld zijn er dan bijeenkomsten, waar mensen meer over open data kunnen leren, plannen kunnen maken om gegevens open te maken en samen kunnen werken om nieuwe toepassingen voor

Regionaal Archief Alkmaar geeft nieuwe beeldcollectie vrij
Het Regionaal Archief Alkmaar heeft een nieuwe dataset met beelden toegevoegd aan de Open Cultuurdata API: foto’s van Alkmaar voor 1900. Al eerder heeft het Regionaal Archief Alkmaar de Bosboom en Bonda fotocollecties vrijgegeven. Net als de beelden in deze
Regionaal Archief Alkmaar geeft nieuwe beeldcollectie vrij
Het Regionaal Archief Alkmaar heeft een nieuwe dataset met beelden toegevoegd aan de Open Cultuurdata API: foto’s van Alkmaar voor 1900. Al eerder heeft het Regionaal Archief Alkmaar de Bosboom en Bonda fotocollecties vrijgegeven. Net als de beelden in deze
