Twitter
Twitter Mailinglist
MailinglistSpelen met open cultuur data: nieuwe technologie
|
Door: Tijmen Schep. Samen met Beeld en Geluid en de Open State Foundation organiseert Kennisland al enkele jaren het Open Cultuur Data Lab. Daarin onderzoeken we samen met musea, archieven en andere kennisinstellingen de Open Data beweging en wat die voor musea kan betekenen. Met veel succes: recent werd het project als voorbeeldstellend aangewezen door de EU, en het heeft er mede toe geleid dat Nederland bovengemiddeld veel Open Cultuur Data projecten heeft gestart en daardoor internationaal vooroploopt. Open data projecten hebben heel eigen vraagstukken. De eerste twee sessies gingen over de definitie van open en de juridische drempels die innovatoren zullen tegenkomen. Is je content auteursrechtelijk gezien wel herbruikbaar? We worstelen al jaren met de complexe aard van het auteursrecht in Europa, en de absurde lengte (tot 70 jaar na de dood van de maker) waar werken ‘op slot zitten’, terwijl in de verre meerderheid van de gevallen niemand meer geld verdient aan de werken. Zonde! De technologische drempelDeze sessie keken we naar de tweede drempel: de technologische. Zelf data delen, of die van anderen gebruiken, daar zijn allerlei oplossingen en standaarden voor bedacht. En wie leuke makers wil aantrekken zal hun taal en hun voorkeuren moeten leren begrijpen. In de Open Cultuur Data reader die Kennisland ook dit jaar weer heeft geüpdate wijzen we allereerst op de functionaliteit die tegenwoordig in veel collectiebeheersoftware zit. Het online delen van je content gebeurt tegenwoordig voornamelijk via zogenaamde API’s. Wat zijn API’s?API’s zijn een eenvoudig idee: in plaats van het maken van ‘1 grote database waar alles inzit’ (iets dat een decennium geleden nog populair was), is er nu een realistischere aanpak om data te koppelen. API’s zijn afspraken over hoe je data uit andermans database mag opvragen via het internet. Je maakt eigenlijk een speciale website die niet voor mensen bedoeld is, maar voor computers. Die kunnen bijvoorbeeld door naar… www.rijksmuseum.nl/api/rembrandt/1650-1660/Amsterdam ..te gaan alle werken opvragen van Rembrand die tussen 1650 en 160 gemaakt zijn in Amsterdam. Hoe je dat webadres moet samenstellen en wat voor lijstje met informatie je dan precies krijgt, dat is precies de afspraak die je maakt. Zo heeft het Rijksmuseum een uitgebreide pagina waarop ze uitleggen wat je precies kan opvragen en hoeveel details je dan terugkrijgt. Daarmee kun je bijvoorbeeld een app bouwen die up-to-date data over de werken van Rembrandt ophaalt bij meerdere musea. Hergebruik stimulerenHet hebben van een API die relevante data kan leveren is een voorwaarde als je wilt dat externe partijen je data gaan gebruiken in hun apps. Veel makers zijn gewend aan de API’s van grote bedrijven en startups uit Silicon Valley. Ze knopen allerlei diensten aan elkaar om zo weer nieuwe diensten te bedenken. Maar als je het hergebruik van je content wilt stimuleren, dan is het in de praktijk helaas niet genoeg om de data beschikbaar te stellen. Je moet idealiter ook op zoek naar de mensen en communities die er iets mee kunnen. Het gebeurt niet vanzelf. Het crowdsourcen van collectiedata kreeg ook aandacht. Een leuke ontwikkeling zijn de zogenaamde ‘scanning parties’ waarin bezoekers het archief in worden geleid en daar objecten 3D scannen. We probeerden het zelf uit: tijdens de sessie leerden we 3D scannen met met onze smartphones.
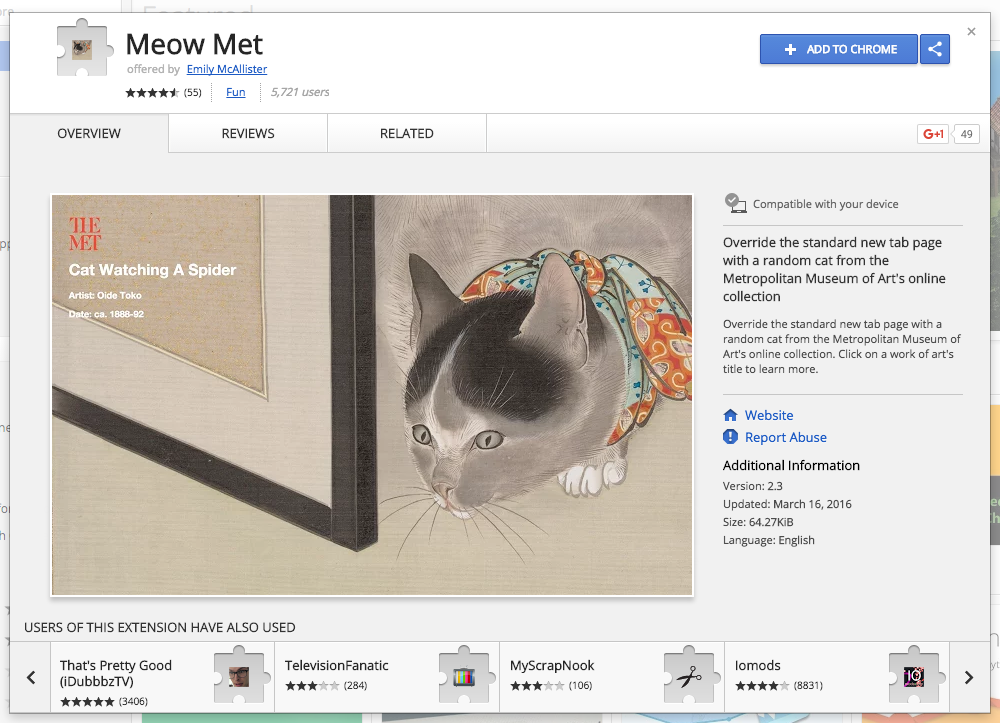
Dat levert geregeld leuke resultaten op. Online kun je steeds meer 3D modellen vinden van Nederlandse museumobjecten (al dan niet stiekem ingescand). Schermen voor kunstCollectiedata komt bij een steeds breder publiek terecht. Een interessante ontwikkeling om bij aan te sluiten is bijvoorbeeld de opkomst van schermen als de Electric Objects en de FRM. Dit zijn beeldschermen die speciaal ontworpen zijn om aan je muur te hangen en (digitale) kunst te tonen. Met een app kun je de kunstwerken vervangen, en kun je je abonneren op kunstenaars (en musea en archieven?). Ook een startup als Electric Objects heeft natuurlijk weer een API zodat je er leuke diensten voor kunst maken. Electric Objects from Electric Objects on Vimeo. Ook bij Kennisland hebben we er eentje hangen, die elke dag een andere kleine uitsnede van de Nachtwacht toont. Het principe kun je op allerlei plakken terugvinden. Je zou bijvoorbeeld ook een oude telefoon kunnen inlijsten en de Muzei app installeren. Daarmee krijgt je telefoon telkens automatisch een nieuwe achtergrond uit een museum. Of installeer de Meow Met plugin voor je browser zodat je bij elke nieuwe browsertab die je opent eerst even een kat uit de collectie van het MET ziet.
Screenshot van Meow Met plugin webpagina. Wat heb je in huis?Het visualiseren van collecties kwam ook aan bod. Want musea en archieven hebben zo enorm veel, hoe wordt je daar wijs in? De verschillende populaire formaten voor schilderijen in het MOMA worden in een grafiek ineens zichtbaar. En ook in Nederland wordt hiermee gespeeld, bijvoorbeeld door Lotte Meijer voor het Boijmans Museum: City Collection Interactive Infographic from Lotte Meijer on Vimeo. Er zit ook een serieuze vragen onder verstopt, die denkers als Lev Manovich aankaarten, zoals: wie bepaalt het canon? Een canon impliceert een selectie van ‘het beste’, maar is het maken van zo’n selectie nog nodig in een digitale wereld? De grote hoeveelheden data die verzameld (kunnen) worden bevragen zo ten dele de rol van musea en archieven als poortwachters van de goede smaak. Algoritmes helpen een handje.Spannende nieuwe datavisualisaties kwamen dit jaar ook uit Google’s ‘cultural institute’ in Parijs. Zij maakten bijvoorbeeld deze enorme ‘wereldkaart van kunst’.
Het interessante is dat ze daarin de beelden inhoudelijk gegroepeerd hebben. Zo zie je in het begin van de tweede animatie, voordat het beeld uitzoomt, dat je bij een ‘kust vol portretten’ begint. Deze groepering is het resultaat vanzogenaamde ‘deep learning’ algoritmes die, na enige training, de onderwerpen van de beelden (landschappen, dieren) zelf kunnen achterhalen. Ook in Nederland worden de mogelijkheden van deze algoritmes onderzocht. In het project ‘Next Rembrandt’ leerde een algoritme door de schilderijen van Rembrand te bekijken de schilderstijl van Rembrand nabootsen. Zo kon het een ‘nieuwe rembrandt’ genereren die in theorie zo van de hand van Rembrand had kunnen komen. Wat is de auteursrechtelijke status van zo’n nieuw werk? Zouden musea en archieven zo zelf nieuwe werken kunnen genereren die dan misschien gebaseerd zijn op de gezichten van bezoekers? promotievideo van het project The Next Rembrandt. Het genereren van nieuw werk uit bestaan werk is een gebied waar we de komende jaren meer ontwikelingen in verwachten. Het lab van de New York Public Library genereerde al eerder geautomatiseerd boekkaften voor boeken die eigenlijk geen leuk plaatje op de voorkant hebben. Wat zou jou organisatie op deze manier kunnen aanvullen? Nieuwsgierigheid gewekt?Dit en meer bespraken we tijdens de derde sessie van het Open Cultuur Data Lab. Kun je er geen genoeg van krijgen? Volg Open Cultuur Data op Twitter om op de hoogte te zijn voor volgende masterclasses. En we raden je aan om de websites van onze partners in de gaten te houden: Beeld en Geluid is een van de meest innoverende open-data organisaties in Nederland, en ook Open State zijn echte open data helden. Zonder hen hadden we niet zoveel plezier kunnen hebben in het werken aan dit doorlopende onderzoeksproject. Last but not least willen we het Netwerk Digitaal Erfgoed bedanken die dit jaar de stuwende kracht achter Open Cultuur Data waren. |